Introduction
The ever-expanding digital universe, where information is a currency and connectivity a necessity, the role of database management stands paramount. At the core of virtually every digital application, from the smallest mobile app to the most extensive enterprise system, databases serve as the backbone, diligently storing, organizing, and retrieving data. This introduction serves as a gateway into the intricate world of database management, shedding light on its significance, fundamental principles, and the pivotal role it plays in our data-driven era. The database is a structured collection of data that allows you for efficient storage, retrieval, and management of information. In a world inundated with a ceaseless flow of data, databases provide the necessary infrastructure to organize this wealth of information systematically.
Types of Databases: A Comparative Overview
Relational Databases (RDBMS):
- Structure: Data is the organized into tables with row and column. Tables can be related through primary and foreign keys.
- Examples: MySQL, PostgreSQL, Oracle Database, Micro SQL Server.
- Advantages: Data integrity through normalization. ACID compliance ensures transaction reliability.
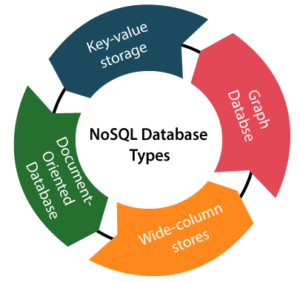
No SQL Databases:
- Structure: Data is stored in various formats, including document-oriented, key-value pairs, wide-column stores, or graph databases.
- Examples: Mongo DB (document-oriented), Redis (key-value), Cassandra (wide-column store), Neo4j (graph).
- Advantages: Flexible schema allows for easy scalability. Suitable for large volumes of unstructured or semi-structured data.
New SQL Databases:
- Structure: Similar to traditional relational databases but designed to address scalability challenges.
- Examples: Google Spanner, Cockroach DB.
- Advantages: Combines ACID properties with improved scalability. Well-suited for global distributed systems.
Graph Databases:
- Structure: Focuses on representing relationships between data entities using nodes, edges, and properties.
- Examples: Neo4j, Amazon, Neptune, ArangoDB.
- Advantages: Efficient for complex relationship-based queries. Suitable for social networks, fraud detection, and recommendation system.
Document-Oriented Databases:
- Structure: Stores data in flexible, JSON-like documents.
- Examples: Mongo DB, Couch DB, Raven DB.
- Advantages: Well-suited for hierarchical or nested data structures. Easily scalable and flexible schema.
Column-Family (Wide-Column) Databases:
- Structure: Stores data in columns rather than rows, suitable for large-scale and distributed storage.
- Examples: Apache Cassandra, HBase.
- Advantages: Excellent for read and write scalability. Well suited for time-series data and analytics.
In-Memory Databases:
- Structure: Data is stored in the computer’s main memory (RAM) for faster retrieval.
- Examples: Redis, Mem cached, SAP HANA.
- Advantages: Significantly faster data access compared to disk-based databases. Ideal for real-time analytics and applications with high-performance requirements.
Time-Series Databases:
- Structure: Optimized for handling time-stamped or time-series data.
- Examples: Influx DB, Prometheus, Open TSDB.
- Advantages: Efficient storage and retrieval of time stamped data. Well-suited for monitoring, IoT, and financial applications.
Spatial Databases:
- Structure: Specialized for storing and querying spatial data, such as geographical information.
- Examples: Post GIS, Mongo DB, (with geospatial indexes).
- Advantages: Supports spatial data types and queries. Ideal for applications dealing with maps, GPS, and location-based services.
Object-Oriented Databases:
- Structure: Stores data in the form of objects, making it suitable for programming language integration.
- Examples: db4o, Object DB.
- Advantages: Allow direct representation of objects used in software development. Supports complex data structures and relationships.
Key functionalities and components associated with a typical database engine
Core Functionalities:
- Data storage: The database engine manages the physical storage of data on disk or in memory. It organizes data in a way that allows for efficient retrieval and updates.
- Data Retrieval: It provides mechanisms for users and applications to query the database and retrieve specific information based on specified criteria.
- Data Modification: The engine allows for the insertion, updating, and deletion of data within the database, ensuring data consistency and integrity.
- Query Processing and Optimization: The engine interprets and processes queries written in a query language (e.g., SQL). It optimizes query execution plans for efficiency.
- Concurrency Control: In multi-user environments, the database engine manages concurrent access to data, preventing conflicts and ensuring transactions occur in a consistent manner.
- Transaction Management: The engine ensures the reliability of transactions by implementing the principles of ACID (Atomicity, Consistency, Isolation, and Durability).
- Indexing: Database engines often use indexes to speed up data retrieval operations. Indexes provide a structured way to locate and access specific rows of data.
Components:
- Query Processor: Interprets and processes queries, determining the most efficient way to retrieve data based on factors like indexes, table relationships, and data distribution.
- Storage Engine: Manages the physical storage and retrieval of data on disk or in memory. It interacts with the underlying file system or storage infrastructure.
- Concurrency Control Manager: Ensures that multiple transactions can be processed concurrently without compromising data consistency. It may use locking mechanisms or isolation levels.
- Transaction Manager: Manages transactions to ensure that they adhere to the principles of ACID. It oversees the beginning, execution, and completion (commit or rollback) of transactions.
- Buffer Manager: Manages a buffer pool in memory to cache frequently accessed data, reducing the need for disk I/O and improving overall performance.
- Security Manager: Enforces security measures, including authentication and authorization, to control access to the database and ensure data integrity.
- Logging and Recovery Manager: Records changes to the database in a transaction log, facilitating recovery in the event of system failures. It ensures durability and consistency.
- Parser and Compiler: Parses and compiles SQL queries into an internal format that the database engine can process and optimize for execution.
Conclusion
Database management is the backbone of today’s data-driven world, influencing how information is organized, accessed, and utilized. As technology evolves, so too does the landscape of database management, presenting new challenges and opportunities. Whether you’re a database administrator, developer, or tech enthusiast, mastering the principles and best practices outlined in this guide is key to navigating the complex and dynamic field of database management.
